Preview
将要讨论的这些算法都是非比较的排序,用到的可能性比较小吧。
Keywords: 最坏情况下界 线性时间排序
先修知识:现在先考虑比较排序。对于一个互异的、适用比较排序的输入数组,我们不需要知道其他的任何信息,只需要观察它们之间的次序信息。只考虑比较操作的话,比较排序可以被抽象为一棵决策树。
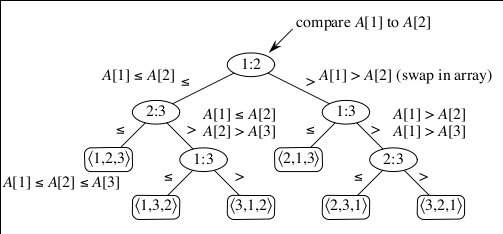
上图的决策树列出了三个元素比较后的六种结果
每次比较后,排序算法会自动确定一部分的顺序,比如走左子树的路径,就一定不会再出现<3,2,1>的情况。对于一个正确的比较排序而言, n 个元素的 n! 种可能的排列都应该出现在决策树上。 从根节点走到叶节点的路径就是算法实际执行的过程。当然,这种简单的决策树和高端算法里的决策树模型相差甚远……
最坏情况的下界
在先修知识里面我们提到了决策树。很明显,当排序的最坏情况发生时,最坏比较次数 = 其决策树的高度h。 由于每种排序结果都至少对应一个可达的叶节点,我们可以知道决策树的叶节点 l 应该满足公式 n! <= l <= 2^h, 其中 n! 指 n 个元素的所有可能排列。
现在考虑n! <= 2^h,两边取对数,得 log(n!) <= h。根据离散数学,斯特林近似公式可以证明有等式 log(n!) = Θ(nlogn),所以决策树的高度h——也就是最坏比较次数——的下界为Ω(nlogn)。这就是由一分为二的决策树的相关知识得出来的,比较排序的最坏情况下界。
计数排序
现在回到非比较排序。接下来提到的三种非比较排序都是线性时间排序。
计数排序的思路是:
- 初始化一个新数组,下标范围是输入数组的最小值到最大值。
- 用新数组储存输入数组中每个数据出现的频次。
- 对这个频次数组迭代,
C[i] = C[i] + C[i-1]。新数组中的各个值的数学意义是下标所代表的元素最后一次出现在排序数组的位置。 - 依据迭代后的新位置数组,逆序排列输入数组。
COUNTING—SORT(A,B,k)
let C[0..k]be a new array
for i=0 to k
C[i]=0
for j=1 to A.length
C[A[j]]=C[A[j]]+1 //C[i]now contains the number of elements equal to i
for i=1 to k
C[i]=C[i]+C[i-1] //C[i] now contains the number of elements less than or equal to i
for j=A.length downto 1
B[C[A[j]]]=A[j]
C[A[j]]=C[A[j]]-1
计数排序的总时间代价为Θ(n+k)。当输入数据的规模k = O(n)时,我们一般会采用计数排序,这样的运行时间为Θ(n)。
基数排序
基数排序针对「d位数上的值」来排序。每一次从低位到高位,对相应d位数上的0~9(对于十进制而言)调用稳定排序(比如计数排序)。通俗地讲,就是先按个位数进行排序,再按十位数再次排序,以此类推,因此基数排序只适用于数字位数少的情形。
基数排序不使用从高位到低位的方法,原因是如果这么做,有一些没有这一位数的数字必须靠在一起形成「段」,并且在下一位数排序的时候,这些没有高位数的数字不能移动出它们所在的「段」,操作起来比较麻烦。
RADIX-SORT(A,d)
for i = 1 to d
use a stable sort to sort array A on digit i
如果在调用稳定排序的时候使用计数排序,那么每一轮的排序耗时Θ(n+k),持续d轮,故基数排序的总时间为Θ(d(n+k)),其中如果d为常数且k = O(n),则基数排序的时间代价为线性。基数排序不是原址排序也不是比较排序。
桶排序
桶排序类似于基数排序,把输入数据按某种规律,比如最高位的值,扔到几个子区间(即桶,也是链表)内,然后再调用其他排序。假设输入数据均匀而独立地分布,那么不会出现很多数据落在同一个桶内的情况。
BUCKET-SORT(A)
n = length[A]
let B[0..n-1] be a new array
for i = 0 to n - 1
make B[i] an empty list
for i = 1 to n
insert A[i] into list B[ ⌊nA[i]⌋ ]
for i = 0 to n-1
sort list B[i] with insertion sort
concatenate the lists B[0],B[1], ..., B[n-1] together in order
桶排序的时间代价分析略。